How to throttle a xen VCPU
This is a tough one. It took me 4 tries just to learn enough to figure out the search terms that could lead me to a useful page. The winning combo was “xen vcpu cap usage”. How about that for cryptic?
As I may have mentioned before (or maybe it’s still in the drafts folder?), I’m trying to work out how to run a ton of small VMs on top of xcp-ng, and part of their smallness is that I want to cap the vcpu speed - as perceived by the virtual machine, the core it’s using should behave as if it’s only running at 1GHz instead of whatever 3-ish GHz the hypervisor itself is running at. This is a difficult proposition.
introductory materials
time management
Obviously, there’s going to be some trickery involved. Having multiple virtual cpus on a single physical core doesn’t somehow duplicate the physical core, and the virtual cpu doesn’t ‘magically’ slow down its processing speed relative to the physical core. I think.
Instead, it looks like what xen does is allocate slices of time in a round-robin format: virtual machine A gets a few milliseconds of execution time, then virtual machine B gets a turn, and so on. This accomplishes the sharing – it lets several virtual cores exist on the same physical core. These timeslices measure the minimum time a VCPU is generally given every time it gets a turn on the physical core. The variable is called tslice_ms, the units are milliseconds, and it can be adjusted at runtime with:
xl sched-credit -s -t 10
Note: in order to actually set the parameters for a whole pool of virtual machines (‘pool’ is defined later on), you have to use the -s argument.
Every time a new VCPU takes a turn on the physical core, the data needed by the new VCPU has to be copied from RAM into the physical core’s cache. This means there is a bare minimum amount of time that each VCPU should be allowed to run in order to improve efficiency – a lot of time would be wasted if a new VCPU was started up, and as soon as it was done with its preparations was shut down again. Thus, timeslices should not be made too short; longer turns, however, mean that VCPUs waiting for their turn can be left waiting for a while and that’s bad for audio processing, where a few tens of milliseconds is a noticable delay. The default timeslice is 30 milliseconds, but for some networking applications, audio, &c. where latency matters, a better timeslice would be closer to 10, 5 or even 1 ms.
Similarly: different VCPUs can be given different priorities, and if a high priority VCPU wakes up and tries to interrupt a low-priority VCPU, then the low-priority VCPU will be interrupted before its timeslice is over. To maintain efficiency and prevent cores from wasting their preparation time, there is a bare minimum execution time guaranteed to every VCPU, regardless of priority. The default for this is 1000 microseconds, which is considered good. The variable is called ratelimit_us, and the unit is microseconds. If it needs to be changed at runtime, the command is:
xl sched-credit -s -r 1000
With me so far? Awesome. Things are gonna get hairy.
what’s a domain?
Xen likes to talk about ‘domains’: dom0, domU, etc. There’s probably some interesting details buried in the theory behind it, but the essence of the matter is that dom0 is the guest virtual machine that manages the hypervisor, and domU refers to virtual machines spun up by the user.



A ‘domain’ is just a strange, xen-specific way of saying ‘virtual machine’.
pools
There’s also a concept called ‘pools’; that’s a collection of physical hypervisor host machines linked together. I don’t know all that’s involved with the linkage, but I think it enhances the ability of the machines to behave as a single, larger host. Among other things, I think it allows VMs to be migrated from one physical host to another.
weights and caps
With the background covered, let’s talk about how to actually limit the apparent speed of a virtual machine. There’s two ways to limit the speed: relative to other VMs (weight), or relative to the physical core speed (cap).
Clear as mud? Keep going.
weight
The weight assigned to a domain (read: virtual machine) can range from 1 to 65535. By default it’s 256.
xl sched-credit -d [domain] -w [weight]
Notice that since we’re making a sched-credit adjustment that’s specific to a domain, the -s argument is unneeded.
A domain with a weight of 200 will get twice as much time on the physical CPU as a domain with a weight of 100, and it will get half as much time as a domain with a weight of 400.
cap
The cap ranges from 0 to 100, and represents the percent of the physical CPU’s time that should be taken up by the particular domain / virtual machine / VCPU. A 100 percent cap means the VCPU get’s the whole core; 50 means the VCPU gets half the core; 0 is the default and means there’s no cap.
xl sched-credit -d [domain] -c [cap]
You can view the current settings with:
xl sched-credit
domain identification
The domains on my server, the one I’ve been doing my experiments on, are shown below.
[19:08 carnap ~]# xl list
Name ID Mem VCPUs State Time(s)
Domain-0 0 2672 8 r----- 78380.3
openbsd 1 1999 1 -b---- 1021.5
Ubuntu Bionic Beaver 18.04 (1) 10 1024 2 -b---- 387.3
Ubuntu Bionic Beaver 18.04 (2) 12 1024 1 -b---- 1789.7
alpine2 15 256 1 -b---- 253.2
alpine linux 1 16 256 1 -b---- 265.1
alpine standard 19 256 1 -b---- 152.1
There’s two commands you can use to get that list:
list_domains
xl list
I assume the first is an alias or wrapper of the second.
Compare the above list to the list of virtual machines as presented by XCP-ng Center.
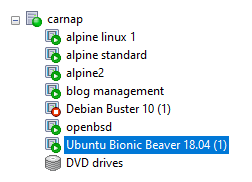
There’s a few things to notice here. First, the name of the VM as given in the image is the same name used by the xl command. Super convenient.
Second, notice that only VMs that are currently running will be shown on the command line list.
Finally: if the name of the VM is changed in XCP-ng Center, the name is not changed in the backend, in that list. Notice that I renamed Ubuntu Bionic Beaver 18.04 (2) to blog management (yes, that’s where I’m hosting the local copy of this blog – Ubuntu Mini is surprisingly convenient), but it’s still got the original name on the command line. It may be waiting for a reboot of the hypervisor, or it may not be.
Just be warned – the first name you pick might be permanent, and you should check for the correct name on the command line.
walkthrough
Note: in order to actually set the parameters for the whole pool, you have to use the -s argument.
Get the domain from the list.
xl list
Change the timeslice to something shorter - 5ms is good, 1ms might be better, depending. Remember to use -s.
xl sched-credit -s -t 5
Set the execution cap for the vm. Since this is relative to the speed of the physical core, check what that speed is:
cat /proc/cpuinfo
You want the line that says cpu MHz. That’s the current speed. The model name line has a speed as well, but that’s just the marketing. I got:
cpu MHz : 3292.542
Since I want to try and run my ‘alpine standard’ VM at 1GHz, the percent I need is:
1 GHz / 3.293 GHz = 0.3037 = 30%
Thus:
xl sched-credit -d 'alpine standard' -c 30
Done. You can test it by spiking the CPU usage on the virtual machine; notice that on the VM, htop will show the usage at 100%, and XCP-ng Center will barely notice an uptick. Spike the usage by copying a ton of zeros into ‘nothing’:
dd if=/dev/zero of=/dev/null
This whole process of capping VCPU usage can be scripted, if you like, for when you start up a new VM. I think there’s also a way to put it in a config script, but I’m not that fancy.